Resumen
Apuntar
El síndrome de dificultad respiratoria aguda (SDRA) es una forma aguda y grave de insuficiencia respiratoria que se caracteriza por una mala oxigenación e infiltrados pulmonares bilaterales. Los avances en el procesamiento de señales y el aprendizaje automático han dado lugar a soluciones prometedoras para la clasificación, la detección de eventos y los modelos predictivos en el tratamiento del SDRA.
Método
En esta revisión, proporcionamos una descripción sistemática de diferentes estudios en la aplicación del aprendizaje automático (ML) y la inteligencia artificial para la gestión, predicción y clasificación del síndrome de dificultad respiratoria aguda (SDRA). Buscamos en las siguientes bases de datos: Google Scholar, PubMed y EBSCO desde 2009 hasta 2023. Se examinaron un total de 243 estudios, de los cuales 52 se incluyeron para su revisión y análisis. Integramos el conocimiento de trabajos previos que proporcionan el estado del arte y la descripción general de los modelos de decisión explicables en el aprendizaje automático y hemos identificado áreas para futuras investigaciones.
Resultados
El aumento de gradiente es el método más común y exitoso utilizado en 12 (23,1%) de los estudios. Debido a la limitación del tamaño de los datos disponibles, la red neuronal y su variación se utilizan en solo 8 (15,4%) estudios. Si bien todos los estudios utilizaron una técnica de validación cruzada o una base de datos separada para la validación, solo 1 estudio validó el modelo con la participación de un médico. Se presentaron métodos de explicabilidad en 15 (28,8%) de los estudios, y el método más común fue la importancia de las características, que se utilizó 14 veces.
Conclusión
En el caso de bases de datos de 5000 muestras o menos, la potenciación extrema del gradiente tiene la mayor probabilidad de éxito. Se requiere una base de datos grande, multirregional y multicéntrica para reducir el sesgo y aprovechar el método de red neuronal. Un marco para validar y explicar el modelo de aprendizaje automático a los médicos involucrados en el manejo del SDRA sería muy útil para el desarrollo y la implementación del modelo de aprendizaje automático.
Introducción
El síndrome de dificultad respiratoria aguda (SDRA) es una complicación común en las unidades de cuidados intensivos (UCI) generales para adultos.1). En 2016, una encuesta realizada en 459 UCI en 50 países demostró que el SDRA se presentaba en el 10% de los pacientes, con una tasa de mortalidad superior al 40% (1). El tratamiento del SDRA en los EE. UU., el Reino Unido y Europa se basa en gran medida en las directrices nacionales de cada país. Aunque estas directrices se crean a partir de encuestas y estudios de investigación a nivel nacional, la calidad de la evidencia para las recomendaciones para la práctica clínica es deficiente y no hay evidencia de alta calidad (2). Esto puede explicar por qué los médicos no siguen las pautas con tanta frecuencia. Por ejemplo, las pautas del Reino Unido recomiendan un volumen corriente bajo de menos de 8 ml/kg y una presión positiva al final de la exposición (PEEP) de más de 12 cmH2O (2). Sin embargo, sólo alrededor del 60% de los pacientes recibieron 8 ml/kg de volumen corriente o menos y más del 82% recibieron menos de 12 cmH2O de PEEP (1Se reconocen enormes variaciones en las prácticas y existe una necesidad urgente de un tratamiento estandarizado y basado en evidencia para el SDRA en la UCI.
El aprendizaje automático (ML) se ha aplicado con éxito en otras áreas, como el procesamiento del lenguaje natural, las aplicaciones de visión artificial y el reconocimiento automático de voz. Como resultado, se han logrado avances en muchas áreas, desde los deportes hasta la robótica, desde el entretenimiento hasta la industria. Las aplicaciones del ML han demostrado un enorme potencial en varios campos médicos, como la predicción de enfermedades, la predicción de resultados clínicos, el diagnóstico y el pronóstico utilizando varias modalidades de datos, incluidas las señales de tiempo y las imágenes médicas.3,4,5,6,7,8,9,10,11,12,13,14,15,dieciséis,17,18).
Aunque el aprendizaje automático tiene la capacidad de reconocer patrones dentro de una gran cantidad de datos, muchos de estos patrones son imperceptibles para los humanos. Estos patrones se pueden utilizar de diferentes maneras para categorizar o predecir eventos (3). Sin embargo, para integrarse con éxito en el sistema de atención de la salud, las aplicaciones de ML deben apuntar a lograr métricas de alto rendimiento, como la precisión, y lograr la confianza de los usuarios hacia la aplicación clínica. Como resultado, la demanda de una mayor transparencia en los modelos de ML en medicina es esencial para una mejor comprensión de la causalidad y la relación entre la entrada y la salida, y para fines legales y éticos (19,20,21).
El concepto de interpretación o explicabilidad en el aprendizaje automático se define como la capacidad del algoritmo de presentar y/o producir conocimiento contenido dentro de los datos de manera que sea perceptible y comprensible para los usuarios.22) Se han utilizado diversos métodos de explicabilidad en la atención médica en general (23) y para los datos de SDRA en particular (24). Sin embargo, pocos estudios han validado realmente la eficacia de estos métodos de explicación con la participación directa de los médicos (23). También falta evidencia sobre qué método es más adecuado para los médicos en términos de su explicabilidad.
El objetivo principal de esta revisión es identificar estudios que hayan utilizado métodos de aprendizaje automático en el tratamiento, pronóstico y diagnóstico de pacientes con SDRA, reflexionar sobre el uso de diferentes bases de datos y métodos de recopilación de datos, algoritmos y su eficacia. La revisión también tiene como objetivo destacar el estado de la explicabilidad en términos de métodos y usos, y el rendimiento de diferentes métodos de aprendizaje automático en el SDRA.
Método
Los criterios de inclusión y exclusión
Se incluyeron en la revisión artículos que emplean aprendizaje automático o inteligencia artificial dirigidos directamente al diagnóstico, tratamiento, evaluación de riesgos, pronóstico o resultado del SDRA. Los artículos incluidos pueden utilizar algoritmos de aprendizaje automático existentes o crear nuevos algoritmos basados en métodos de aprendizaje automático clásicos, como árboles de decisión, o métodos más avanzados, como redes neuronales, o ambos. Se excluyeron protocolos, comentarios, cartas, artículos con solo resúmenes, actas de conferencias, artículos que no estaban en inglés ni habían sido revisados por pares. Solo se seleccionaron estudios que utilizaban datos exclusivamente humanos. Se excluyó la investigación que utilizaba pacientes pediátricos.
Estrategia de búsqueda
Se realizó una extensa búsqueda bibliográfica en Pubmed, Google Scholar y EBSCO en julio de 2023. El resumen del proceso de detección se informa en el diagrama PRISMA (Fig. 1) También se realizó una búsqueda aleatoria con el método de bola de nieve en Google para identificar resultados adicionales. Las palabras clave utilizadas para estas búsquedas incluyen “síndrome de dificultad respiratoria aguda”, “SDRA”, “lesión pulmonar aguda”, “ALI”, “aprendizaje automático” e “inteligencia artificial”. Se utilizaron los operadores booleanos “AND” y “OR” para las búsquedas en Pubmed y EBSCO. La lista de referencias de todos los resultados también se examinó por título y resumen para buscar citas potencialmente relevantes. Se incluye la lista de contribuciones de los autores a este artículo.
Figura 1Diagrama PRISMA para esta revisión. Los autores verificaron todos los registros para determinar su elegibilidad. De un total de 243 estudios identificados a partir de Google Scholar, EBSCO, PubMed y la revisión de referencias, se incluyeron 52 estudios en esta revisión.
Imagen de tamaño completoTodos los resultados de la búsqueda se recopilaron utilizando su título y resumen. La versión de texto completo de estos resultados se utilizó para la selección según los criterios del apartado 2.1. En esta etapa se excluyeron los artículos que no contenían el texto completo. Este proceso lo llevaron a cabo de forma independiente TT y MT para eliminar el sesgo y los desacuerdos se resolvieron con el consenso de todos los autores.
Resultados
Resultados de búsqueda y proceso de selección
La búsqueda en Google Scholar arrojó 54 resultados después de una selección preliminar. Se excluyeron tres artículos que no estaban en inglés, dos resultados que aún no habían sido revisados por pares, un artículo duplicado y 27 artículos irrelevantes. También se excluyó un artículo duplicado.
La búsqueda se repitió con las bases de datos EBSCO y Pubmed, dando como resultado 88 artículos y 85 artículos respectivamente. Finalmente, se seleccionaron 52 artículos para revisión que cumplían con todos los criterios enumerados en Los criterios de inclusión y exclusión Sección (Tabla 1).
Tabla 1 Resumen de los estudios incluidos en esta revisión sistemáticaMesa de tamaño completoCaracterísticas de los estudios revisados
Se seleccionaron cincuenta y dos artículos entre 2009 y 2023. 18 (34,6%) de estos se centraron en la predicción del desarrollo de SDRA en pacientes durante la hospitalización. 14 (26,9%) artículos de publicaciones estaban relacionados con la precisión diagnóstica. 11 (21,2%) artículos se centraron en categorizar a los pacientes con SDRA en grupos o subgrupos según la gravedad o la mortalidad. Cinco artículos estaban relacionados con el uso de ML para predecir la mortalidad de los pacientes o crear un manejo más adecuado para los pacientes. Hay un solo artículo (1,9%) sobre el pronóstico o la trayectoria de salud del SDRA y 1 (1,9%) artículo sobre el uso de ML para modelar la condición de los pacientes con SDRA. Esto se puede ver en la (Fig. 2).
Figura 2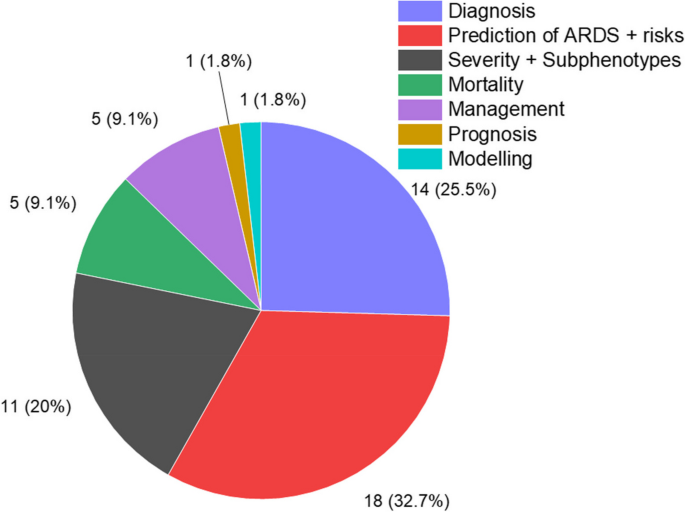
Gráfico circular de los artículos que estudian las aplicaciones del aprendizaje automático en el síndrome de dificultad respiratoria aguda. Nótese que el número total no es 52 porque algunos artículos se centraron en más de un aspecto
Imagen de tamaño completoEn resumen, hay 49 sistemas ML diferentes implementados. El algoritmo más común es el bosque aleatorio con 17 (32,7%) usos. Una variación diferente de algoritmos de aumento de gradiente también es muy común con 13 (25%) XGBoost, 4 (7,7%) adaboost y 7 (13,5%) otros. Los métodos de redes neuronales y sus variaciones también fueron menos frecuentes con 8 (15,4%) redes neuronales (NN), 1 (1,9%) redes neuronales profundas (DNN), 2 (3,8%) redes neuronales recurrentes (RNN) y 3 (5,8%) redes neuronales convolucionales (CNN) para 14 (26,9%) en total. También se probaron los modelos existentes basados en ML, por ejemplo, ALI sniffer, Dense-Ynet y ResNet-50 (Fig. 3).
Fig. 3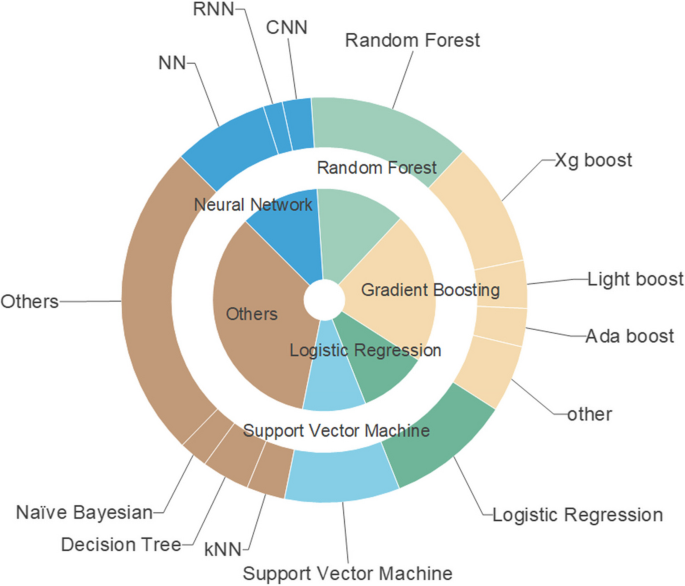
Resumen del método de aprendizaje automático a partir de los estudios de nuestra revisión de sistemas
Imagen de tamaño completoLa definición y los fenotipos del SDRA se definieron recientemente utilizando la definición de Berlín y se actualizaron en 2023 (76). Por lo tanto, a lo largo de los años se han hecho varios intentos de establecer un subfenotipo más riguroso utilizando el algoritmo ML. Se utilizaron algoritmos no supervisados con cierto éxito. Sinha (31) utilizaron análisis de clases latentes para separar a los pacientes en estados hiper e hipoinflamatorios. Zhang et al.(38) en 2019 y Liu et al. (53) en 2021 ambos intentaron categorizar a los pacientes con SDRA en 3 subfenotipos utilizando el método de potenciación de gradiente basado en árboles y el método k-mean respectivamente. Aunque el algoritmo ML ha demostrado un gran potencial para…